大语言模型的演进之路:从 GPT 到多模态时代
发布日期:2026-04-15
人工智能领域在过去几年经历了一场前所未有的变革。大语言模型(LLM)从最初的文本补全工具,逐步演化为能理解、推理、创造的通用智能助手。本文将回顾这段激动人心的技术演进历程。
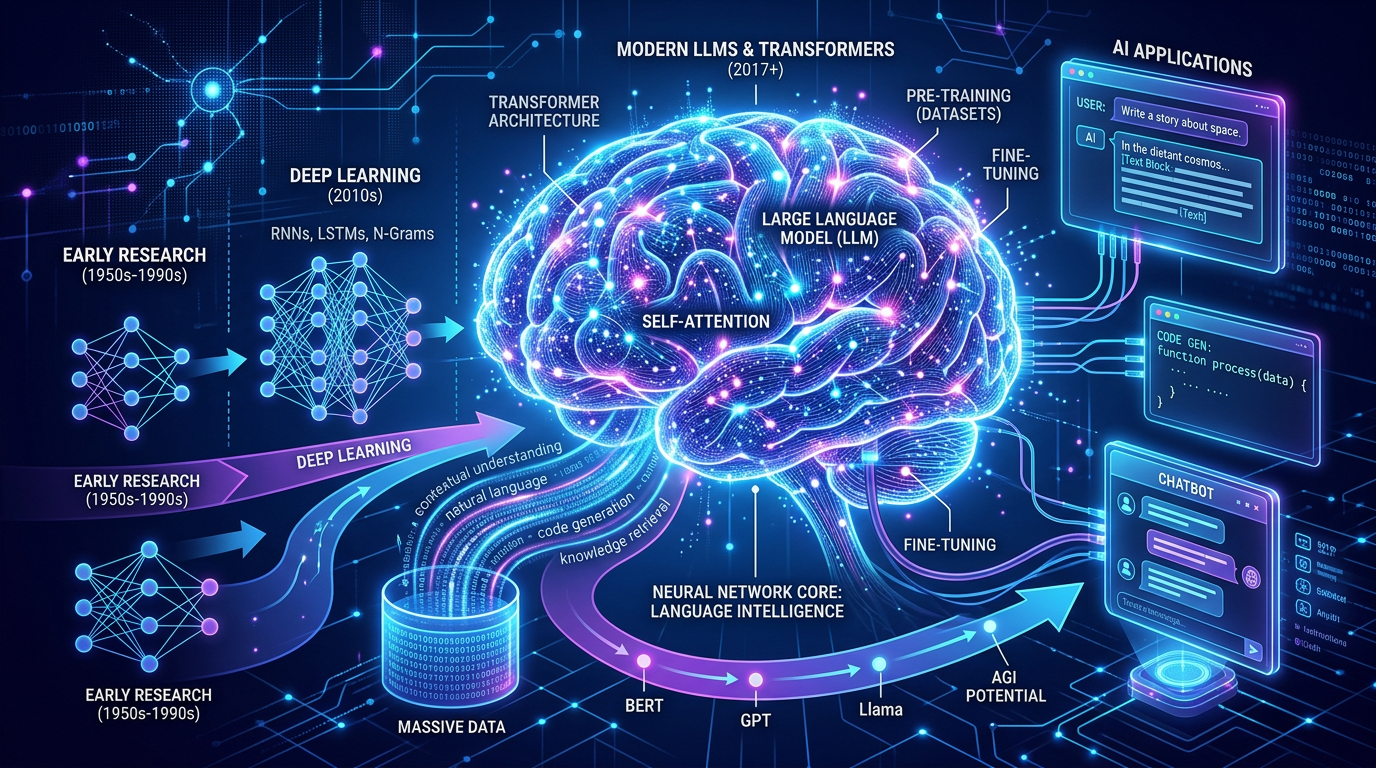
起源:Transformer 架构的诞生
2017 年,Google 发表了划时代的论文《Attention Is All You Need》,提出了 Transformer 架构。这一架构彻底改变了自然语言处理的格局:
- 自注意力机制:允许模型在处理序列时关注任意位置的信息,突破了 RNN 的长距离依赖限制
- 并行计算:相比 RNN 的串行处理,Transformer 可以并行处理整个序列,大幅提升训练效率
- 可扩展性:架构天然支持模型规模的扩展,为后续的大模型奠定了基础
输入序列 → 编码器(自注意力 + 前馈网络) × N → 上下文表示
↓
输出序列 ← 解码器(自注意力 + 交叉注意力 + 前馈网络) × NGPT 系列的崛起
GPT-1:预训练 + 微调范式
2018 年 OpenAI 推出 GPT-1,首次验证了「大规模无监督预训练 + 任务特定微调」的范式。虽然模型参数只有 1.17 亿,但它证明了预训练的巨大潜力。
GPT-2:涌现的语言生成能力
GPT-2 将参数量扩大到 15 亿,展现出了令人惊叹的文本生成能力。OpenAI 最初甚至因为担心被滥用而延迟发布。这一版本让人们第一次意识到:语言模型不仅能理解语言,还能创造语言。
GPT-3:少样本学习的突破
参数量跃升至 1750 亿的 GPT-3 带来了质的飞跃。它展示了强大的 few-shot learning 能力——仅通过几个示例,就能完成从未专门训练过的任务。这预示着通用人工智能的曙光。
GPT-4 与多模态
GPT-4 不仅在语言理解和推理能力上大幅提升,还加入了图像理解能力,标志着大语言模型正式进入多模态时代。
技术关键突破
1. 指令微调(Instruction Tuning)
通过使用大量的「指令-响应」对进行微调,模型学会了遵循人类的各种指令。这使得原本只会「续写文本」的模型变成了能「回答问题、执行任务」的助手。
2. RLHF(人类反馈强化学习)
RLHF 是让 AI 助手变得有用且安全的关键技术:
- 收集偏好数据:让人类标注员对模型的多个输出进行排序
- 训练奖励模型:学习人类的偏好标准
- 强化学习优化:使用 PPO 算法让模型的输出更符合人类期望
3. 上下文窗口的扩展
从 GPT-3 的 2048 tokens 到如今的 128K 甚至百万级 tokens,上下文窗口的扩展让模型能够处理更长的文档、维持更长的对话,大大拓展了应用场景。
开源生态的繁荣
大语言模型并非只有闭源玩家。开源社区同样蓬勃发展:
| 模型 | 开发者 | 参数量 | 特点 |
|---|---|---|---|
| LLaMA | Meta | 7B-70B | 高效训练,开源先驱 |
| Mistral | Mistral AI | 7B-8x22B | 混合专家架构,性价比高 |
| Qwen | 阿里巴巴 | 7B-72B | 中文能力突出 |
| DeepSeek | DeepSeek | 7B-236B | 推理能力强大 |
| ChatGLM | 智谱 AI | 6B-130B | 中英双语优化 |
对开发者的影响
作为一名开发者,我深刻感受到 LLM 带来的变革:
- 编程辅助:AI 编程助手已经成为日常开发的标配工具,代码补全、Bug 修复、代码审查都有了 AI 的参与
- 文档生成:技术文档、API 文档的编写效率大幅提升
- 学习加速:遇到新技术、新框架,可以通过 AI 快速了解核心概念和最佳实践
- 创意激发:在系统设计、架构决策时,AI 可以提供不同视角的方案参考
展望未来
大语言模型的发展远未到终点。以下几个方向值得关注:
- 推理能力的增强:从简单的模式匹配到真正的逻辑推理
- 多模态融合:文本、图像、音频、视频的统一理解与生成
- 个性化定制:为每个用户、每个场景量身定制的 AI 助手
- 边缘部署:更小、更快的模型在移动设备和嵌入式设备上运行
技术的浪潮永不停息,而我们正处在最激动人心的时代。
本文是「AI 技术分享」系列的第一篇,后续将深入探讨 Prompt Engineering 和 AI 辅助编程等话题。